


In my last segment, I spoke briefly about the differences in M365’s content storage options and which option is best suited to which purpose. I then spent some time discussing the importance of a well-thought-out content management foundation layer and how the rigidity and stability of that foundation support flexibility on the user level.
As promised, in this segment we will discuss the building blocks you’ll be using to build your foundation, or if we’re building it for you, your Mint Content Framework (trademark pending, I’m sure.)
Metadata
Simply put, metadata is data that tells us something important about other data. I know, that sounds really convoluted. Here, take a look at these screen shots:
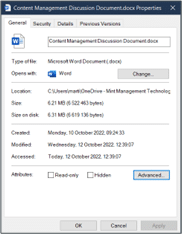
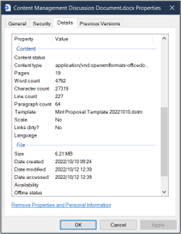
I went into my Windows Explorer, right-clicked on a file, and selected “Properties”. This little window popped up detailing information like my file’s size, name, path, age, last modified date, access permissions, word count, and more.
This is the file’s METADATA.
SharePoint allows us to extend this metadata and include other information in the document properties, e.g. department name, document type, client name, and more.
Taxonomy
If metadata is data that tells us something about a file, taxonomy is the practice of formalizing those file properties into a reusable classification system, e.g. a company-wide list of departments users can choose from. By creating an enterprise-wide taxonomy, we allow users to identify, store, display, group, filter, and search content far more effectively than if they were dealing with file names alone.
Imagine we’re uploading an agenda for a meeting to be held next Tuesday. We’d probably want to classify it something like this:
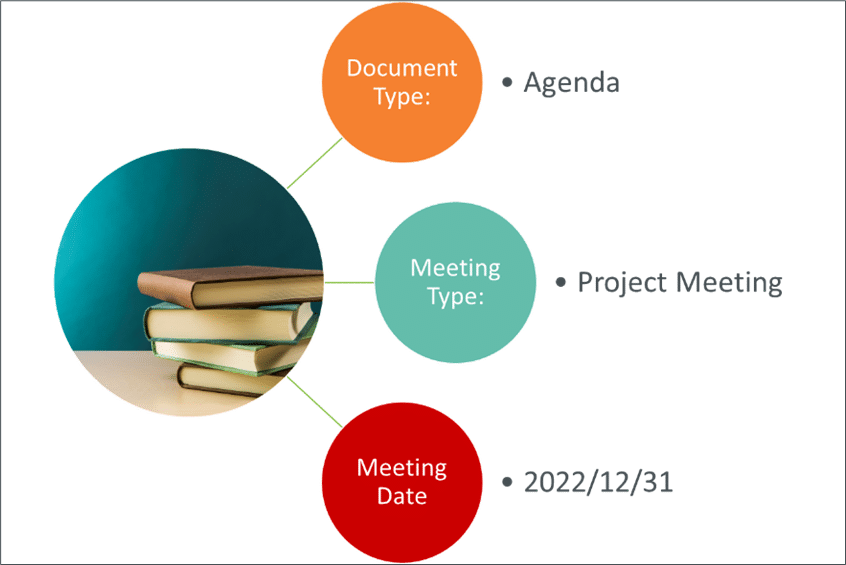
With the meeting type, document type, and meeting date captured in the document properties (metadata), finding the document in future becomes a far simpler task because these properties can be used to search, filter, sort, and more.
When we create an enterprise-wide taxonomy, we provide a predictable structure to these metadata values. So if we create a list of departments users can choose from, the whole company can use the same references, which simplifies tasks like filtering search results. No more not finding a document because you misspelled the department name in your search box.
Content Types
Just as taxonomy lends structure to properties we want to track, content types use our taxonomy structures to help us “templatize” the way we work with documents of the same type.
Here’s an example:
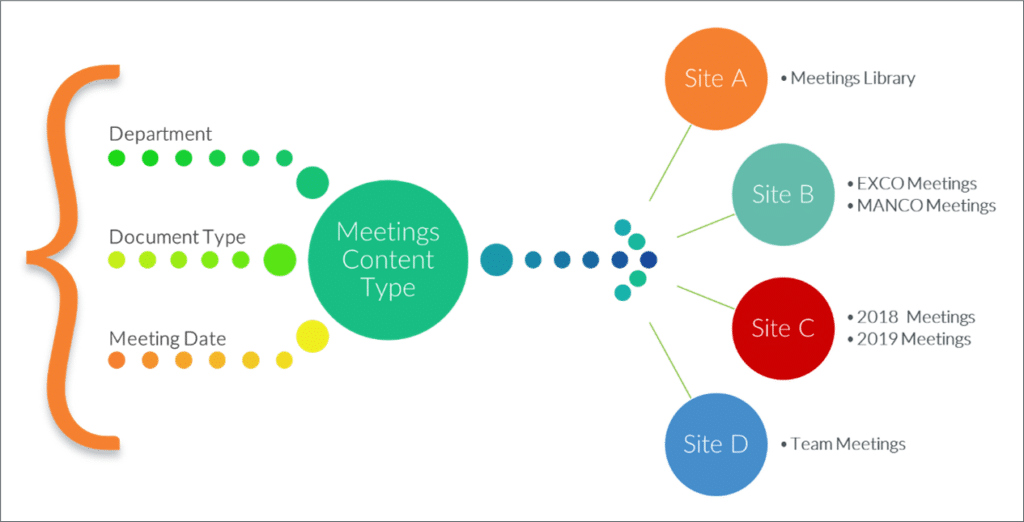
Our company has thousands of users who regularly attend and participate in meetings, both internal and client meetings. We know that every meeting generates specific documents, such as agendas, minutes, meeting packs, and so on. The company needs to keep and track these documents for contractual reasons and it’s difficult to do this effectively when we don’t have a single standard.
While we know that the types of meetings and the topics of discussion will differ from meeting to meeting, we also know the information we need to track will be the same across all meeting documents, such as:
- Department
- Meeting Type
- Meeting Date
- Document Type
- Internal / External attendees (maybe?)
So we can build a content type that allows us to capture this information for any meeting document we upload.
When we create our “meetings” content type, we tell SharePoint which of the metadata properties in our taxonomy are relevant – in this case, let’s say department, document type, and meeting date:
SharePoint then takes those properties and packages them together neatly in our “meetings” content type.
Once the content type is published, it becomes available to all sites in our environment. If a site administrator wants to create a library intended to store meeting documents, the administrator simply connects that library to the “meetings” content type and all the relevant taxonomies are instantly available. No fuss, no muss.
It gets better.
Once a document is uploaded into one of our new meeting libraries, the metadata used to classify that document will travel with it. So if the department later splits into multiple teams and that document has to be moved to a new site, the act of moving it will not destroy the metadata, so you don’t have to re-tag anything. Just move it to its new home. And if the department decides to implement, say, an automated archiving service, the metadata on the file will tell the automated service when to move it – and you will still be able to search and filter for it in the archive space using the metadata you applied.
Sites
SharePoint sites come in a number of different flavors, but they are all used to house apps, lists, and libraries.
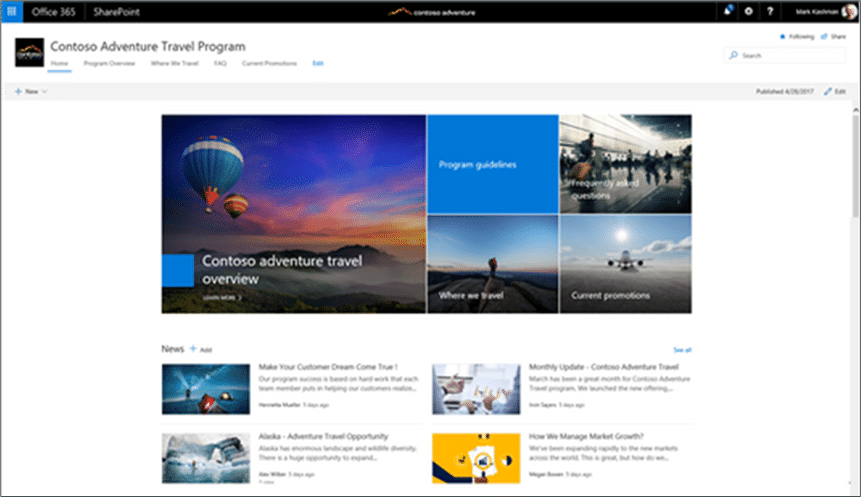
In this example we have a Communications site, with a navigation bar (to access the libraries, etc.) along the top and news, quick links, social media feeds, etc. make up the body of the page.
Hubs
Hub sites are used to visually group a set of sites together. For instance, if our company wanted to group all HR-related sites together, we could create a hub site called “HR” and then have sites connected to that hub for recruitment, employee benefits, leave management, and so on.
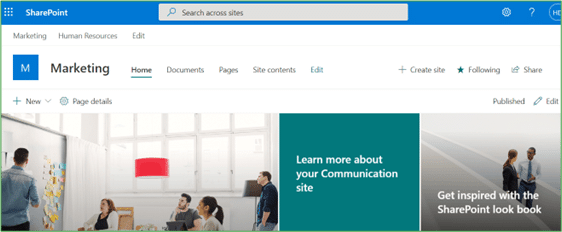
Our marketing site above is connected to a hub – we can see the global / hub navigation in the top white bar (Marketing / Human Resources) and the Marketing site’s own local navigation below that (Home, Documents, Pages, etc.)
Whenever we need to visit a different site from the one we’re on, we simply click on that site’s name in the hub navigation, and if we need to move between libraries on our current site, we click on the link in the local navigation bar.
Apps, Lists and Libraries
SharePoint generically refers to any object, from a container for storing data to a graph on the landing page as an app. However, when dealing with containers for storing content, all apps are divided into two categories: Lists and Libraries.
Lists
Lists store structured data – a bit like an Excel spreadsheet. Each entry goes into a separate row, with columns for all the information that needs to be captured.
Libraries
Libraries store unstructured data, in other words, files. Libraries can house documents, videos, images, and more. Libraries can house document properties (metadata) in columns we can build views with that filter, group, and sort information into whatever layout we need.
Views
Think of views as fancy pivot tables that allow us to make sense of large volumes of data. Views let us change the way we look at data in a list or documents in a library, based on the information we want to get out.
Take a look at this Financials library:
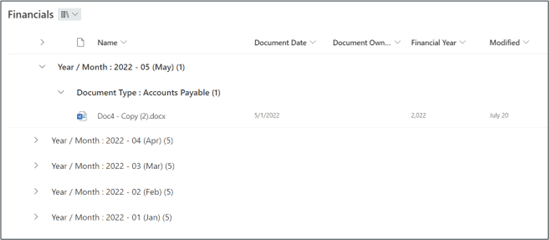
In our library columns we can see the document date, owner, financial year, etc., and if we look down the left side of the page, we can see groupings by year / month and document type. We could just as easily have grouped our documents the other way round:
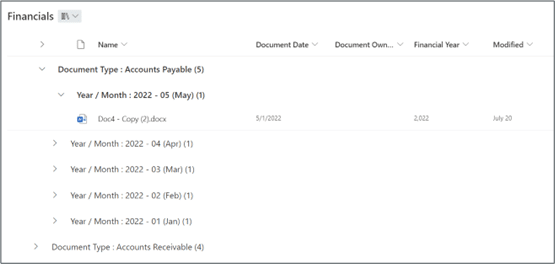
We can create as many different views on a particular list or library as we want, depending on user requirements. Views are quick and easy to create, without ever needing to physically move a single document.
Yes, I know, burn the witch.
I’ve specifically excluded THE F-WORD from this segment and if it were possible, we would never utter that cursed word in these hallowed halls again. Unfortunately there’s no side-stepping it, so next time I will discuss folders and why I hate them more than brussels sprouts.
Until then, stay safe and healthy, and look both ways before crossing the street.
